独家丨美团领投 A 轮, Mindverse 总融资 5000 万美元,打造持续学习的 Agent 模型
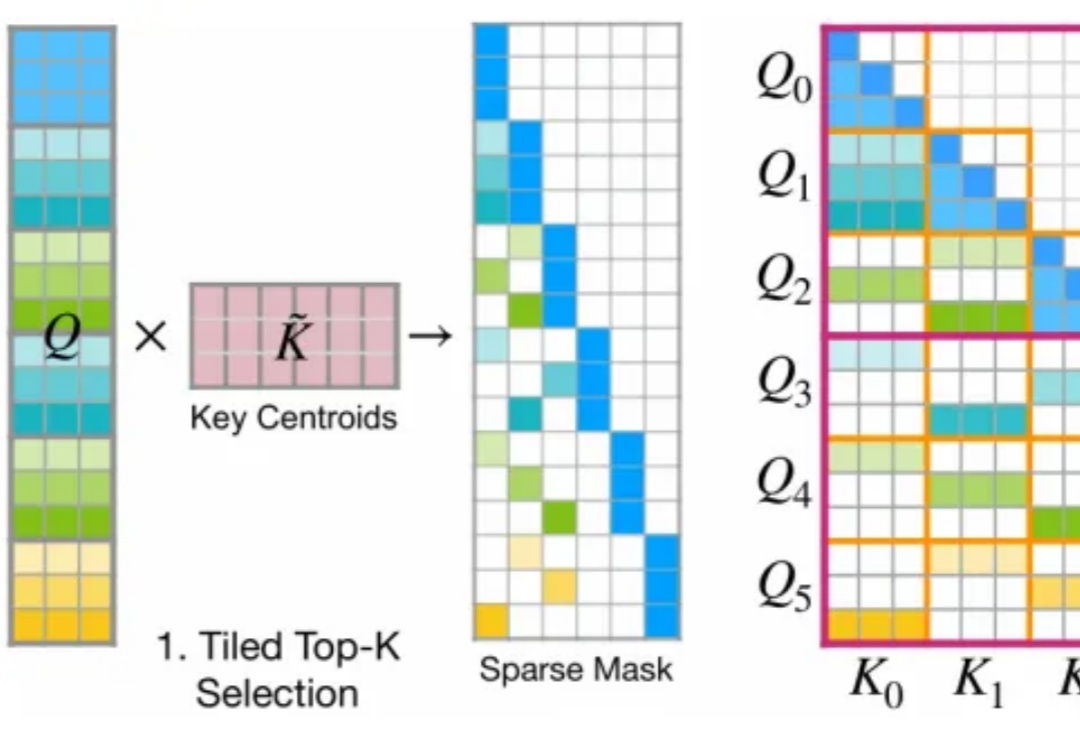
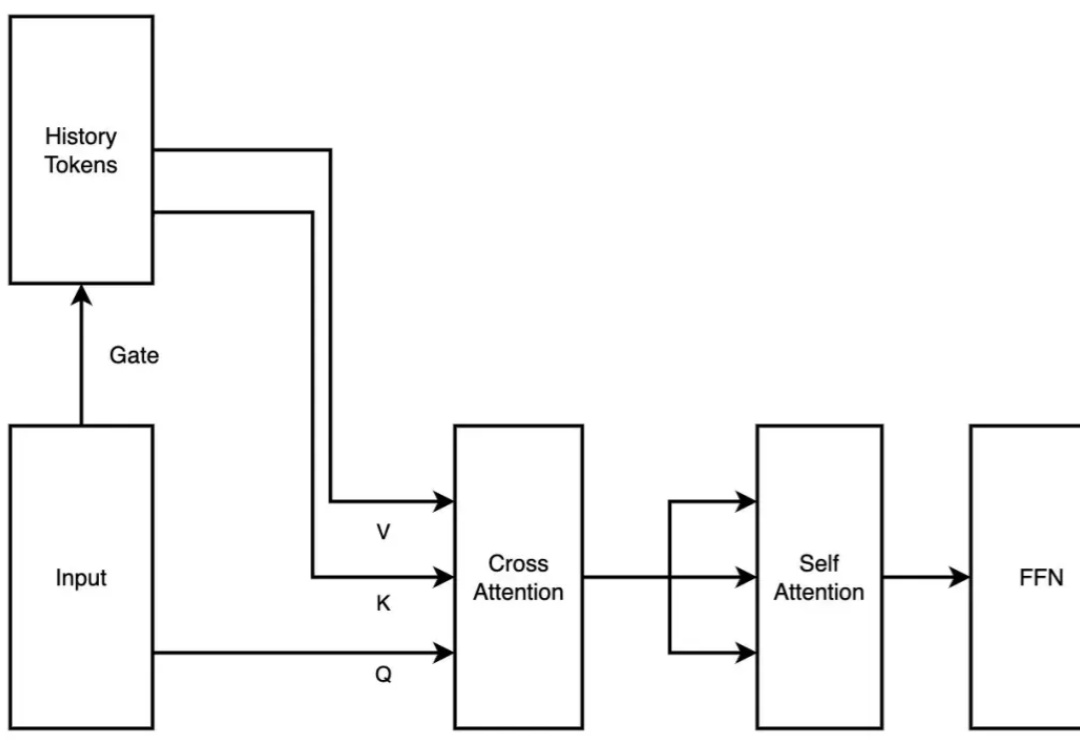
独家丨美团领投 A 轮, Mindverse 总融资 5000 万美元,打造持续学习的 Agent 模型Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。
来自主题: AI资讯
8254 点击 2026-06-01 19:20